春节期间,科技界最热的新闻,莫过于DeepSeek开发的人工智能助手在全球范围内掀起热潮。作为AI领域的璀璨明珠,大模型正引领我们步入一个充满无限想象与可能的新时代。如今,通用大模型已成为未来人工智能技术和产业生态的核心。国内大模型企业经历了从“大炼模型”到“炼大模型”的范式转变,并在智能体、多模态等模式上持续创新,生态体系日益完善。当前,模型的训练推理效率及性能显著提高。通过优化深度学习框架、迭代专用硬件以及算法创新,不仅大幅缩短了训练时间,降低了计算资源消耗,还在推理阶段提升了运行效率和响应速度。然而,在参数规模不断扩张的情况下,模型训练的成本和能源消耗不断增加也是不争的事实,这也成为行业前行需要逾越的难关。中国工程院院士刘韵洁指出,目前大模型多局限于单一地点训练,面临电力和算力资源难以承受的问题,而协同训练可从多地点分布式开展,既减轻单一地点负担,又能提高训练效率,目前已实现分钟级解决排队问题,且多个异地训练效率能达到单点训练的80%。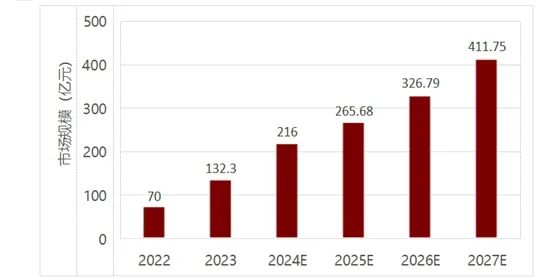 2022—2027年中国通用大模型市场规模预测(资料来源:赛迪四川)
2022—2027年中国通用大模型市场规模预测(资料来源:赛迪四川)
赛迪四川在《2024AI大模型行业调查研究报告》(以下简称:《报告》)中分析认为,我国通用大模型市场规模在2022年约为70亿元,2023年突破130亿元,预计到2027年将突破400亿元,年均增速超25%。《报告》指出,随着未来产业基础建设持续增长、大模型应用替换、生成式人工智能带来的增量市场和人工智能赋能的企业级应用拓展,通用大模型市场将逐渐成熟。在通用大模型产业,从企业分类看:百度、阿里、腾讯、华为等科技领军企业有全面布局能力,领跑市场;科大讯飞、商汤科技等AI垂类企业在模型层和应用层竞争优势独特;智谱华章、百川智能、月之暗面等初创企业凭借技术优势和创新精神快速兴起。从产业链看,通用大模型包括基础层、工具/平台层和模型层。基础层提供基础设施与技术支持;工具/平台层汇聚相关企业,提供模型开发与应用工具;模型层汇聚研发及应用企业。该模型已成为人工智能应用创新的重要驱动力,在自然语言处理、计算机视觉和语音识别等领域取得突破进展。从应用生态看,越发丰富多元,涉及教育、医疗健康、金融科技等诸多领域,催生出大量大模型业务应用场景。开源与闭源模式在模型开发与应用中互补共生,降低开发者入门门槛,加速新技术普及,且能提供更专业、稳定的服务。通用大模型的商业模式正在渐趋形成,从路径来看,当前主要还是“通用大模型+行业定制模型”。具有数据、算力和算法综合优势的企业将模型整合为基座大模型,通过低门槛、高效率的大模型开发与部署平台,向各行各业提供大模型服务。主要盈利方式包括交易量收费、定制开发费用、数据服务费用和订阅收费等。通用大模型在落地中存在诸多痛点,如数据安全与隐私保护、成本与效益平衡、内容可信度与质量可控以及技术创新与社会责任平衡等。解决这些痛点,建议政府相关部门完善顶层设计,规范数据标准,健全监管体系;企业要和科研机构合作,以应用为导向强化具体场景应用,树立长远投资视角,健全风险管理体系;用户要根据需求选产品,注意数据安全,向开发者反馈,共同推动通用大模型技术发展。未来,通用大模型将呈现出大小模型并行、融合多模态数据、端云协同和算网协同等发展趋势,能兼顾规模与效率、提供更丰富信息、实现任务均衡分配和资源优化调配。通用大模型市场前景广阔,行业盈利空间较大,但盈利能力尚待提升。随着技术的不断成熟和应用场景的拓展,相信大模型将在更多垂直领域实现深度应用,撬动各行各业的智能化转型。刘韵洁院士也曾提出,国内模型企业如果能够在通用大模型基础上,把行业数据训练好、做好行业大模型,“完全可以走出中国道路”。


 2022—2027年中国通用大模型市场规模预测(资料来源:赛迪四川)
2022—2027年中国通用大模型市场规模预测(资料来源:赛迪四川)
